Lovely Professional University 2011 B.Tech Computer Science and Engineering Artificial intelligence and logic programming assignment-2 solution - Question Paper
PART: A
Q1:- Mention the differences ranging from BFS and DFS using examples. Can we use these searching techniques in Search engine?
ANS: DFS (Depth 1st Search) and BFS (Breadth 1st Search) are search algorithms used for graphs and trees.
In a breadth 1st search, you begin at the root node, and then scan every node in the 1st level starting from the leftmost node, moving towards the right. Then you continue on scanning the 2nd level (starting from the left) and the 3rd level, and so on until you've scanned all the nodes, or until you obtain the true node that you were searching for.
1. A BFS searches every single solution in a graph to expand its nodes; a DFS burrows deep within a child node until a goal is reached.
2. The features of a BFS are space and time complexity, completeness, proof of completeness, and optimality; the most natural output for a DFS is a spanning tree with 3 classes: forward edges, back edges, and cross edges.
Breadth 1st Search Depth 1st Search
Advantages
Optimal solutions are always obtained
Multiple solutions obtained early May arrive at solutions without examining much of search space
Will not go down blind alley for solution Needs little memory (only node in current path needs to be stored)
Disadvantages
If solution path is long, the whole tree must be searched up to that depth May settle for non-optimal solution
All of the tree generated must be stored in memory May explore single unfruitful path for a long time (forever if loop exists!)
The depth-first search traversal of above graph will be:
A B E F C D
The breadth-first search traversal of above graph will be:
A B C D E F
Yes we can use these techniques in search engine. As we enter characters by characters it begins searching in its database and will obtain out the exact word which we were searching for.
Q2:- Compare hill climbing with steepest hill climbing discuss with the help of an example.
ANS:
Hill climbing is a mathematical optimization technique which belongs to the family of local search. It is an iterative algorithm that begins with an arbitrary solution to a problem, then attempts to obtain a better solution by incrementally changing a single element of the solution. If the change produces a better solution, an incremental change is made to the new solution, repeating until no further improvements can be obtained.
For example, hill climbing can be applied to the travelling salesman issue. It is easy to obtain an initial solution that visits all the cities but will be very poor compared to the optimal solution. The algorithm begins with such a solution and makes small improvements to it, such as switching the order in which 2 cities are visited. Eventually, a much shorter route is likely to be found.
Hill climbing in which you generate all successors of the current state and select the best one. These are identical as far as many texts are concerned. A useful variation on simple hill climbing considers all the moves from the current state and chooses the best 1 as the next state. This method is called steepest –ascent hill climbing or gradient search.
In simple hill climbing, the 1st closer node is chosen, whereas in steepest ascent hill climbing all successors are compared and the nearest to the solution is chosen. Both forms fail if there is no closer node, which may happen if there are local maxima in the search space which are not solutions. Steepest ascent hill climbing is similar to best-first search, which tries all possible extensions of the current path instead of only one.
Example: To apply steepest- ascent hill climbing to the colored blocks problem, we must consider all perturbations of the initial state and select the best. For this issue this is difficult since there are so many possible moves. There is a trade-off ranging from the time needed to choose a move and the number of moves needed to get a solution that must be considered when deciding which method will work better for a particular issue. Usually the time needed to choose a move is longer for steepest – ascent hill climbing and the number of moves needed to get to a solution is longer for basic hill climbing
Q3:- Solve the subsequent cryptarithmetic puzzle using constraint satisfaction?
SEND+MORE=MONEY.
ANS: Solving a cryptarithm by hand usually involves a mix of deductions and exhaustive tests of possibilities. For instance, the subsequent sequence of deductions solves Dudeney's SEND + MORE = MONEY puzzle above (columns are numbered from right to left):
1. From column 5, M = one since it is the only carry-over possible from the sum of 2 single digit numbers in column 4.
2. To produce a carry from column four to column 5, S + M is at lowest 9, so S is eight or 9, so S + M is nine or 10, and so O is 0 or 1. But M = 1, so O = 0.
3. If there were a carry from column three to column four then E = nine and so N = 0. But O = 0, so there is no carry, and S = 9.
4. If there were no carry from column two to column three then E = N, which1 is impossible. Therefore there is a carry and N = E + 1.
5. If there were no carry from column one to column 2, then N + R = E mod 10, and N = E + 1, so E + one + R = E mod 10, so R = 9. But S = 9, so there must be a carry from column one to column two and R = 8.
6. To produce a carry from column one to column 2, we must have D + E = 10 + Y. As Y cannot be 0 or 1, D + E is at lowest 12. As D is at most 7, then E is at lowest 5. Also, N is at most 7, and N = E + 1. So E is five or 6.
7. If E were six then to make D + E at lowest 12, D would have to be 7. But N = E + 1, so N would also be 7, which is impossible. Therefore E = five and N = 6.
8. To make D + E at lowest 12 we must have D = 7, and so Y = 2.
PART:B
Q4:- elaborate the problems faced in knowledge representation?
ANS: The problem that arise while using knowledge representation techniques are:
i. Important Attributes: any attribute of objects is so basic that they occur in almost every issue.
ii. Relationship among attributes: any important relationship that exists among objects attributes?
iii. Choosing granularity: at what level of detail should the knowledge be represented?
iv. Set of objects: how sets of objects should be represented?
v. Finding right structure: provided a large amount of knowledge stored, how can, relevant parts be accessed?
Q5:- elaborate differences ranging from propositional logic and predicate logic? Illustrate with example.
ANS: A proposition is a statement, which in English would be declarative sentence. Every proposition can be either actual or false. But in predicate logic we represent that real world facts are statements written as coff's.
Propositional logic fails to capture the relationship ranging from any individual being a men and that individual being a mortal for this we need variables and qualifications.
In propositional logic a complete sentence can be presented as an atomic proposition. and complex phrases can be created using AND, OR, and other operators.....these propositions has only actual of false values and we can use truth tables to describe them...
like book is on the table....this is a single proposition...
In predicate logic there are objects, properties, functions (relations) are involved.
Q6:- Differentiate ranging from matching and indexing.
ANS: Matching:
1. Till now we have used search to solve the issues as the application of improper rules.
2. We applied them to individual issue states to generate new states to which the rules can then be applied, until a solution is obtained.
3. We suggest that a clever search involves choosing from among the rules that can be applied at a particular point, but we do not talk about how to extract from the entire collection of rules those that can be applied at a provided point.
4. To do this we need matching.
Indexing
a. Do a simple search through all the rules, comparing every one's precondition to the current state and extracting all the ones that match.
b. But this has 2 issues
i. In order to solve very interesting issues , it will be necessary to use a large number of rules, scanning through all of them at every step of the search would be hopelessly inefficient.
ii. It is not always immediately obvious whether a rule's preconditions are satisfied by a particular state.
c. To solve the 1st problem, use simple indexing. Eg. In Chess ,combine all moves at a particular board state together.

ASSIGNMENT-2
Submitted to:
Ms. Ruchi Vinayak
Submitted By:
Shikha Kumari
Roll no-20
Section-A1811
PART: A
Q1:- Mention the differences between BFS and DFS using examples. Can we use these searching techniques in Search engine?
ANS: DFS (Depth First Search) and BFS (Breadth First Search) are search algorithms used for graphs and trees.
In a breadth first search, you start at the root node, and then scan each node in the first level starting from the leftmost node, moving towards the right. Then you continue scanning the second level (starting from the left) and the third level, and so on until youve scanned all the nodes, or until you find the actual node that you were searching for.
1. A BFS searches every single solution in a graph to expand its nodes; a DFS burrows deep within a child node until a goal is reached.
2. The features of a BFS are space and time complexity, completeness, proof of completeness, and optimality; the most natural output for a DFS is a spanning tree with three classes: forward edges, back edges, and cross edges.
|
Breadth First Search |
Depth First Search |
|
Advantages |
|
|
Optimal solutions are always found Multiple solutions found early |
May arrive at solutions without examining much of search space |
|
Will not go down blind alley for solution |
Needs little memory (only node in current path needs to be stored) |
|
Disadvantages |
|
|
If solution path is long, the whole tree must be searched up to that depth |
May settle for non-optimal solution |
|
All of the tree generated must be stored in memory |
May explore single unfruitful path for a long time (forever if loop exists!) |
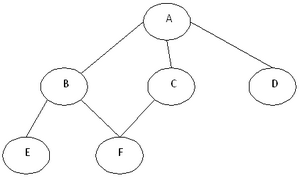
The depth-first search traversal of above graph will be:
A B E F C D
The breadth-first search traversal of above graph will be:
A B C D E F
Yes we can use these techniques in search engine. As we enter characters by characters it starts searching in its database and will find out the exact word which we were searching for.
Q2:- Compare hill climbing with steepest hill climbing Explain with the help of an example.
ANS:
Hill climbing is a mathematical optimization technique which belongs to the family of local search. It is an iterative algorithm that starts with an arbitrary solution to a problem, then attempts to find a better solution by incrementally changing a single element of the solution. If the change produces a better solution, an incremental change is made to the new solution, repeating until no further improvements can be found.
For example, hill climbing can be applied to the travelling salesman problem. It is easy to find an initial solution that visits all the cities but will be very poor compared to the optimal solution. The algorithm starts with such a solution and makes small improvements to it, such as switching the order in which two cities are visited. Eventually, a much shorter route is likely to be obtained.
Hill climbing in which you generate all successors of the current state and choose the best one. These are identical as far as many texts are concerned. A useful variation on simple hill climbing considers all the moves from the current state and selects the best one as the next state. This method is called steepest ascent hill climbing or gradient search.
In simple hill climbing, the first closer node is chosen, whereas in steepest ascent hill climbing all successors are compared and the closest to the solution is chosen. Both forms fail if there is no closer node, which may happen if there are local maxima in the search space which are not solutions. Steepest ascent hill climbing is similar to best-first search, which tries all possible extensions of the current path instead of only one.
Example: To apply steepest- ascent hill climbing to the colored blocks problem, we must consider all perturbations of the initial state and choose the best. For this problem this is difficult since there are so many possible moves. There is a trade-off between the time required to select a move and the number of moves required to get a solution that must be considered when deciding which method will work better for a particular problem. Usually the time required to select a move is longer for steepest ascent hill climbing and the number of moves required to get to a solution is longer for basic hill climbing
Q3:- Solve the following cryptarithmetic puzzle using constraint satisfaction?
SEND+MORE=MONEY.
ANS: Solving a cryptarithm by hand usually involves a mix of deductions and exhaustive tests of possibilities. For instance, the following sequence of deductions solves Dudeney's SEND + MORE = MONEY puzzle above (columns are numbered from right to left):
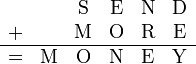
1. From column 5, M = 1 since it is the only carry-over possible from the sum of two single digit numbers in column 4.
2. To produce a carry from column 4 to column 5, S + M is at least 9, so S is 8 or 9, so S + M is 9 or 10, and so O is 0 or 1. But M = 1, so O = 0.
3. If there were a carry from column 3 to column 4 then E = 9 and so N = 0. But O = 0, so there is no carry, and S = 9.
4. If there were no carry from column 2 to column 3 then E = N, which1 is impossible. Therefore there is a carry and N = E + 1.
5. If there were no carry from column 1 to column 2, then N + R = E mod 10, and N = E + 1, so E + 1 + R = E mod 10, so R = 9. But S = 9, so there must be a carry from column 1 to column 2 and R = 8.
6. To produce a carry from column 1 to column 2, we must have D + E = 10 + Y. As Y cannot be 0 or 1, D + E is at least 12. As D is at most 7, then E is at least 5. Also, N is at most 7, and N = E + 1. So E is 5 or 6.
7. If E were 6 then to make D + E at least 12, D would have to be 7. But N = E + 1, so N would also be 7, which is impossible. Therefore E = 5 and N = 6.
8. To make D + E at least 12 we must have D = 7, and so Y = 2.
PART:B
Q4:- What are the issues faced in knowledge representation?
ANS: The issue that arise while using knowledge representation techniques are:
i. Important Attributes: any attribute of objects is so basic that they occur in almost every problem.
ii. Relationship among attributes: any important relationship that exists among objects attributes?
iii. Choosing granularity: at what level of detail should the knowledge be represented?
iv. Set of objects: how sets of objects should be represented?
v. Finding right structure: given a large amount of knowledge stored, how can, relevant parts be accessed?
Q5:- What are differences between propositional logic and predicate logic? Illustrate with example.
ANS: A proposition is a statement, which in English would be declarative sentence. Every proposition can be either true or false. But in predicate logic we represent that real world facts are statements written as coffs.
Propositional logic fails to capture the relationship between any individual being a men and that individual being a mortal for this we need variables and qualifications.
In propositional logic a
complete sentence can be presented as an atomic proposition. and complex
sentences can be created using AND, OR, and other operators.....these
propositions has only true of false values and we can use truth tables to
define them...
like book is on the table....this is a single
proposition...
In predicate logic there are objects, properties,
functions (relations) are involved.
Q6:- Differentiate between matching and indexing.
ANS: Matching:
1. Till now we have used search to solve the problems as the application of appropriate rules.
2. We applied them to individual problem states to generate new states to which the rules can then be applied, until a solution is found.
3. We suggest that a clever search involves choosing from among the rules that can be applied at a particular point, but we do not talk about how to extract from the entire collection of rules those that can be applied at a given point.
4. To do this we need matching.
Indexing
a. Do a simple search through all the rules, comparing each ones precondition to the current state and extracting all the ones that match.
b. But this has two problems
i. In order to solve very interesting problems , it will be necessary to use a large number of rules, scanning through all of them at every step of the search would be hopelessly inefficient.
ii. It is not always immediately obvious whether a rules preconditions are satisfied by a particular state.
c. To solve the first problem, use simple indexing. Eg. In Chess ,combine all moves at a particular board state together.
| Earning: Approval pending. |