Institute of Chartered Financial Analysts of India (ICFAI) University 2009 C.A Chartered Accountant Integrated Professional Competence (IPCC) - Information Technology Revision Test s (ember ) - Ques
Download the subsequent attachment:
PAPER - 7 : INFORMATION TECHNOLOGY AND STRATEGIC MANAGEMENT SECTION - A : INFORMATION TECHNOLOGY QUESTIONS
|
Definitions | ||
|
1. Define the following terms briefly: | ||
|
(i) BIOS |
(ii) ASCII | |
|
(iii) VPN |
(iv) Bluetooth | |
|
(v) Joystick |
(vi) SCSI | |
|
(vii) Management Database |
(viii) Mirror Log | |
|
(ix) Program Debugging |
(x) Repeater | |
|
(xi) Fat Client |
(xii) DDE | |
|
(xiii) Key |
(xiv) EFT | |
|
(xv) Decision Table |
(xvi) Flowchart | |
|
(xvii)Web Browser |
(xviii) Hollerith Code | |
|
(xix) Virus |
(xx) Buffering | |
|
Number System Conversion | ||
|
2. Convert the following from one number system to another number system | ||
|
working notes: | ||
|
II o 2) CO |
)2 | |
|
(ii) (100101.101)2 = ( |
)10 | |
|
(iii) (730)8 = ( |
)16 | |
|
(iv) (45.AB)16 = ( |
)10 | |
|
Usage | ||
|
3. Give one or more reasons of use for each of the following: | ||
|
(i) Cache Memory |
(ii) HTML | |
|
(iii) Firewall |
(iv) Off-line Storage | |
|
(v) Spooling Software |
(vi) Distributed Database | |
|
(vii) CRM |
(viii) Motherboard | |
|
(ix) Dependent Data Mart |
(x) NIC | |
|
(xi) CMOS |
(xii) Proxy Server | |
|
(xiii) DDL |
(xiv) URL | |
|
(xv) File Pointer |
(xvi) Router | |
|
(i) |
First Generation Computers and Second Generation Computers |
|
(ii) |
LAN and WAN |
|
(iii) |
Liquid Inkjet Printer and Solid Inkjet Printer |
|
(iv) |
Serial File Organization and Sequential File Organization |
|
(v) |
Hierarchical Database Structure and Network Database Structure |
|
(vi) |
RAM and ROM |
|
(vii) |
Star Topology and Ring Topology |
|
(viii) |
System Flowcharts and Run Flowcharts |
|
(ix) |
Intranet and Extranet |
|
(x) |
B2B and B2C |
|
(xi) |
Circuit Switching and Packet Switching |
|
(xii) |
Limited Entry Decision Table and Extended Entry Decision Table |
Introduction to Computers
5. (a) Computers are helpful but they have certain limitations also. Please explain this
statement briefly.
(b) Describe the various characteristics of storage on which storage devices can be classified, and also characterize various types of storage.
(c) What are the factors that determine the number of characters that can be stored on a floppy diskette?
Input and Output Devices
6. (a) What is a mouse? How a mouse may be classified?
(b) What do you mean by image processing? Briefly explain the various steps involved in document imaging.
Software
7. (a) What is an operating system? Write the various functions performed by an operating
system.
(b) What do you understand by an expert system (ES)? Mention different types of ES and discuss the components of an ES briefly.
File organizations
8. (a) Briefly discuss various direct access file organization techniques with their
advantages and disadvantages.
(b) What factors need to be given attention to, while determining best file organization for a particular application? Which file organization is best suited for storing payroll records of all employees in the finance department? Explain briefly.
Databases
9. (a) What problems led to the evolution of databases and what are the benefits of DBMS
solution?
(b) Elucidate the various functions performed by a database administrator.
Data Warehouse
10. (a) What is a data warehouse? Why and how data warehouses evolved?
(b) What are the advantages and concerns in using data warehouses?
Networking Concepts
11. (a) What is a computer network? In what ways can a computer network help a
business?
(b) Explain the various functions of communications software.
Local Area Networks and Network Security
12. (a) Explain the concept and working of WLANs.
(b) Describe the primary components of an Intrusion Detection System (IDS).
Client/Server Technology
13. (a) Which limitations of traditional computing models led to the emergence of
Client/Server technology?
(b) Describe 3-tier architecture with its advantages. State the reasons why 3-tier architecture is required.
Data Centers
14. (a) Define data center. What challenges are faced by the management of data center?
(b) Define business continuity plan (BCP). What are the components of a BCP? Enumerate the phases in the life cycle of a BCP.
Internet
15. (a) Discuss the various applications of Internet briefly.
(b) Write down the various features of electronic mail software, in brief.
Electronic Commerce
16. (a) Explain the reasons behind the Internet's dramatic impact on the scope of business
networking applications.
(b) What is Supply Chain Management (SCM)? What problems must be addressed by it?
(c) Define Electronic Data Interchange (EDI). Explain the working of EDI.
Introduction to Flowcharting
17. (a) What do you understand by program analysis and algorithm? Explain with an
example.
(b) What is the relevance of flowchart in system programming? Describe the various categories of flowcharts.
Flowchart
18. Draw a flow chart to compute and print Income-tax, Surcharge and Education cess on the income of a person, where income is to be read from terminal and tax is to be calculated as per the following rates:
Slab (Rs.)
Rate No tax
@ 10% of amount above 1,00,000
Rs. 5,000 + 20% of amount above 1,50,000
Rs. 25,000 + 30% of amount above 2,50,000
@ 10% on the amount of total tax, if the income of a person
exceeds Rs. 10,00,000
2% on the total tax
(i) 1 to 1,00,000
(ii) 1,00,001 to 1,50,000
(iii) 1,50,001 to 2,50,000
(iv) 2,50,001 onwards Surcharge
Education cess Decision Table
19. (a) What is a decision table? Briefly discuss its advantages and disadvantages.
(b) A computer file has customer name, type, bill number, bill date, amount and the date of payment. If the customer is a dealer and pays his bills within 30 days, 10% discount is allowed. If it is between 30 to 45 days, discount and surcharge are zero. If he pays after 45 days, he has to pay 10% surcharge. The corresponding percentages for a manufacturer are 121/2%, 0, 121/2%.
Prepare a decision table for the above situation.
Short Notes
20. Write short notes on the following:
(i) OCR
(ii) Bullwhip Effect
(iii) Program Library Management System Software
(iv) TCP/IP
(v) Graph Plotter
SUGGESTED ANSWERS/HINTS
1. (i) BIOS: It stands for Basic Input Output system. It is a small chip on the motherboard that includes start up code, the set up program and also loads the hardware settings required to operate various devices like keyboard, monitor, disk drives, etc.
(ii) ASCII: It stands for American Standard Code for Information Interchange. It is used to represent data in main computer memory. It uses the rightmost seven bits of the 8-bit byte to represent numbers, letters and special characters. The 8th bit is used for parity or it may be permanently 1 or 0.
(iii) VPN: It stands for Virtual Private Network. It is a private network that uses a public network (usually the Internet) to connect remote sites or users together. Instead of using a dedicated, real-world connection, a VPN uses virtual connections routed through the Internet from the company's private network to the remote site or employee.
(iv) Bluetooth: Bluetooth is a telecommunications industry specification that describes how mobile phones, computers, and personal digital assistants (PDAs) can be easily interconnected using a short-range wireless connection.
(v) Joystick: It is a screen pointing input device. It is a vertical lever usually placed in a ball socket, which can be moved in any direction to control cursor movements around the screen, for computer games and some professional applications.
(vi) SCSI: Small Computer System Interface (SCSI) is a device interface that is used to solve the problem of a finite and possibly insufficient number of expansion slots. Instead of plugging interface cards into the computer's bus via the expansion slots, SCSI extends the bus outside the computer by way of a cable.
(vii) Management Database: Management databases store data and information extracted from selected operational and external databases. They consist of summarized data and information most needed by the organization's managers and other end users as part of decision support systems and executive information systems to support managerial decision making. They are also called information databases.
(viii) Mirror Log: It is an optional database file which is a copy of a transaction log (a file that records database modifications) and provides additional protection against the loss of data in the event the transaction log becomes unusable. It has a file extension of .mlg.
(ix) Program Debugging: Cleansing the computer program from errors is called program debugging. Towards this purpose, the programmers devise a set of test data transactions to test the various alternative branches in the program. The
results got from the computer are compared with the ones derived manually prior to computer processing. If the results do not tally, the programmer then verifies the flowcharts and code in a search for the bugs and then fixes the bugs.
(x) Repeater: It is a device that solves the snag of signal degradation which results as data is transmitted along the various cables. It boosts or amplifies the signal before passing it through to the next section of cable.
(xi) Fat Client: In two-tier architecture, a client is called as a fat client if the business logic and the presentation layer are located on the client machine and data layer is on the server machine. The entire processing load is on the client. It imposes a lot of memory and bandwidth requirement on the client's machine.
(xii) DDE: Direct Data Entry (DDE) refers to entry of data directly into the computers through machine readable source documents. It does not require manual transcription of data from original paper documents. DDE devices can scan source documents magnetically or optically to capture data. Examples of such devices include magnetic ink character readers and optical character readers.
(xiii) Key: In the context of relational databases, a key is a set of one or more columns whose combined values are unique among all occurrences in a given table. A key is the relational means of specifying uniqueness.
(xiv) EFT: EFT stands for Electronic Funds Transfer and represents the way the business can receive direct deposit of all payments from the financial institution to the company's bank account. Once the user signs up, money comes to him directly and sooner than ever before. Examples of EFT systems in operation include Automated Teller Machines (ATMs) and Point-of-Sale transactions.
(xv) Decision Table: A decision table is a table listing all the possible contingencies that may be considered within the program, together with the corresponding actions to be taken. Decision tables permit complex decision-making criteria to be expressed in a concise and logical format.
(xvi) Flowchart: A flowchart is a diagram, prepared by the programmer, of the sequence of steps, involved in solving a problem. It shows the general plan, architecture, and essential details of the proposed structure. It is an essential tool for programming and it illustrates the strategy and thread of logic followed in the program.
(xvii) Web Browser: A Web browser is a special client software package which is used to view Web pages on the Internet. It fetches a Web page from a server using a standard HTTP request. Some of the popular browsers are Internet Explorer, Netscape Navigator, Mozilla Firefox, and Opera.
(xviii) Hollerith Code: Hollerith Code is used for representing alphanumeric data on punched cards. Each card column holds one character. Each decimal digit, letter, and special character is represented by one, two or three holes punched into designated row positions of the column.
(xix) Virus: A virus is a program that instructs the operating system to append it to other programs and thus propagates to other programs via files containing macros which are sent as attachments to electronic mail messages. A virus can be benign like it can cause minor disruptions by printing laughing messages or can be malignant like it can delete files or corrupt other programs.
(xx) Buffering: Buffering is a process that enables the processor to execute another instruction while input or output is taking place rather than being idle while transfer is completed.
|
2. (i) (692)10 = ( )2 | |||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||
|
(692)10 = (100101.101)2 = |
(1010110100)2
( )10
1 x 25 + 0 X 24 + 0 x 23 + 1 x 22 + 0 x 21 + 1 x 20 + 1 x 2-1 + 0 x 2-2 + 1 x 2-3
1 x 32 + 0x 16 + 0x 8 + 1 x 4 + 0x 2 + 1 x 1 + 1 x 0.5 + 0x.25 + 1 x 0.125
32 + 0 + 0 + 4 + 0 + 1 + 0.5 + 0 + 0.125 (37.625)10
(iii) (730)8 = ( )16
To convert the given number from Octal number system to Hexadecimal number system, each digit of the number will be represented in Binary form using a group of three bits.
=111 011 000 Now we need to regroup each 3-bit Binary form into 4-bit Binary form as follows-:
= 0001 1101 1000 = 1 D 8 = (1D8)16
(iv) (45.AB)16 = ( )10
= 4 * 161 + 5 x 160 + 10 X16-1 + 11 x 16-2 = 4 * 16 +5 x 1 + 10 x 0.0625 + 11 x 0.00390625 = 64 + 5 + 0.625 + 0.04296875 = (69.66796875)10
3. (i) Cache Memory: The cache memory acts as temporary memory and boosts processing power of the processor significantly. To retrieve any data, first the cache is searched and then the primary memory is searched. Access from cache memory is even faster than primary memory.
(ii) HTML: Hypertext Markup Language (HTML) is a coding language used to create Hypertext documents for use on the World Wide Web. It allows the creator of a Web page to specify how text will be displayed and how to link to other Web pages, files and Internet services.
(iii) Firewall: A firewall is a hardware/software system that controls the flow of traffic between the Internet and the organization's internal Local Area Networks and systems. It is set up to enforce the specific desired security policies. It is an effective means of protecting the organization's internal resources from unwanted intrusion.
(iv) Off-line Storage: It is a system where the storage medium can be easily removed from the storage device. It is used for data transfer and archival purposes. In modern computers; floppy disks, optical disks and flash memory devices including USB drives are commonly used for off-line mass storage purposes.
(v) Spooling Software: The purpose of spooling software is to compensate for the speed differences between the computer and its peripheral devices. These programs take the results of computer programs and move them from primary memory to disk. The area on the disk where the program results are sent is
commonly called the output spooling area. Thus, the output device can be left to interact primarily with the disk unit, not the CPU. It can also be used on the input side.
(vi) Distributed Database: Distributed database systems facilitate savings in time and costs by concurrent running of application programs and data processing at various sites. They usually reduce costs for an organization because they reduce transfer of data between remote site and the organization's headquarters. They may also provide organizations with faster response times for filling orders, answering customer requests, or providing managers with information.
(vii) CRM: Customer Relationship Management (CRM) enables the organizations to manage their customers in a better way through the introduction of reliable systems, processes and procedures. It also includes improving customer service. It allows a business to maintain all customer records in one centralized location that is accessible to the entire organization through password administration.
(viii) Motherboard: The motherboard or the system board is the main circuit board on the computer. It acts as a direct channel for the various components to interact and communicate with each other. It has two or more expansion slots also to add new components to the computer.
(ix) Dependent Data Mart: A dependent data mart is a physical database that receives all its information from the Data Warehouse. Its purpose is to provide a subset of the data of the Data Warehouse for a specific purpose or to a specific sub-group of the organization.
(x) NIC: Network Interface Card (NIC) is an electronic card which is installed in server as well as in all the nodes for interconnection of nodes with server. It provides the connector to attach the network cable to a server or a workstation. The on-board circuitry then provides the protocols and commands required to support it. It has additional memory for buffering incoming and outgoing data packets, thus improving the network throughput.
(xi) CMOS: The personal computer uses the CMOS (Complementary Metal Oxide Semiconductor) memory to store the date, time and system setup parameters. These parameters are loaded every time the computer is started. A small lithium ion battery located on the motherboard powers the CMOS.
(xii) Proxy Server: A proxy server is designed to restrict access to information on the Internet. If an organization wishes to restrict or prohibit the flow of certain types of information to its network, a proxy server can be employed there.
(xiii) DDL: Data Definition Language (DDL) defines the conceptual schema providing a link between the logical (the way the user views the data) and physical (the way the data is stored physically) structures of the database. It is used to define the physical
characteristics of each record, field in the record, field's data type, field's length, field's logical name and also to specify relationships among the records.
(xiv) URL: Uniform Resource Locators (URLs) are used by Web Browsers to address and access individual Web pages, Web sites and Internet resources. The format of a URL is: protocol/Internet address/Web page address.
Example: http://www.icai.org/seminars.html
(xv) File Pointer: File pointers establish linkage between records in a database organization. A pointer is the address of another related record that is "pointed to and it directs the computer system to that related record. It is placed in the last field of a record; if more than one pointer is used, then in the last fields.
(xvi) Router: Routers are hardware devices used to direct messages across a network on the basis of network addresses contained in the packets. They supply the user with network management utilities. They can be used to interconnect different types of networks. They help to administer data flow by such means as redirecting data traffic to various peripheral devices or other computers by selecting appropriate routes in the event of possible network malfunctions or excessive use.
|
S.No. |
First Generation Computers |
Second Generation Computers |
|
1. |
These computers employed vacuum tubes. |
These computers employed transistors and other solid state devices. |
|
2. |
They were large in size. |
They were smaller in size. |
|
3. |
They used a great amount of electricity and generated a lot of heat, due to which they required air conditioning. |
They required lesser power and generated lesser heat. |
|
4. |
Input and output units were punched card readers and the card punches. |
Input and output units were magnetic tapes. |
|
5. |
They were slow in terms of processing speed. |
They were comparatively faster in processing. |
|
6. |
They relied on machine language to perform operations. |
They used symbolic or assembly languages. |
|
7. |
UNIVAC (Universal Automatic Computer) was the first general purpose electrical computer. IBM-650 was the most popular first generation computer. |
IBM 1401 was the most popular second generation computer. |
For more details of the above points, students are advised to refer to the study material Chapter - 1, Unit - 1, Section - 1.1.
|
S.No. |
LAN |
WAN |
|
1. |
A Local Area Network (LAN) is a group of computers and network devices connected together, usually within the same building, campus or spanned over limited distance. |
A Wide Area Network (WAN) is not restricted to a geographical location, although it might be confined within the bounds of a state or country. The scale is much greater than in LAN. |
|
2. |
Communication channels between the machines are usually privately owned. |
Communication channels between the machines are usually furnished by a third party. |
|
3. |
Channels are relatively high capacity and error-free. |
Channels are relatively low capacity and error-prone. |
|
4. |
LAN uses a shared physical media which is routed in the whole campus. |
WAN uses point-to-point links between systems. |
|
5. |
LAN enables multiple users to share software, data, and devices. |
WAN does not allow sharing of resources. |
|
6. |
Inexpensive transmission media and inexpensive interface devices are used. |
Expensive transmission media and expensive interface devices are used. |
|
7. |
Data transmission rates are high (0.1 to 30 Mbps). |
Data transmission rates are up to few thousand bits per second. |
(iii) Liquid Inkjet Printer: Liquid inkjet printers use ink cartridges from which they spray ink onto the paper. A cartridge of ink attached to a print head with 50 or so nozzles, each thinner than a human hair, moves across the paper. The number of nozzles determines the printer's resolution. A digital signal from the computer tells each nozzle when to propel a drop of ink onto the paper. On some printers, this is done with mechanical vibrations.
Solid Inkjet Printer: Solid Inkjet printers use solid ink sticks that are melted into a reservoir and sprayed in precisely controlled drops onto the page where the ink immediately hardens. High-pressure rollers flatten and fuse the ink to the paper to prevent smearing. These printers are sometimes referred to as phase-change printers because the ink moves from a solid to a liquid phase to be printed, and then back to a solid phase on the page. As a final step, the paper moves between two rollers to cold-fuse the image and improves the surface texture.
(iv) Serial File Organization: With serial file organization, records are arranged one after another, in no particular order other than the chronological order in which records are added to the file. It is commonly found with transaction data, where records are created in a file in the order in which transactions take place. Records are sometimes processed in the order in which they occur. For example, when such a file consists of daily purchase and payment transaction data, it is often used to update records in a master account file. Since transactions are in random order of key field, in order to perform this update, records must be accessed randomly from the master file.
Sequential File Organization: In a sequential file, records are stored one after another in an ascending or descending order determined by the key field of the records. It is suitable for batch processing applications like payroll application, where the records may be organized sequentially by employee codes. Such files are normally stored on storage media such as magnetic tape, punched paper tape, punched cards, or magnetic disks. To access these records, the computer must read the file in sequence from the beginning. The first record is read and processed first, then the second record in the file sequence, and so on. To locate a particular record, the computer program must read each record in sequence and compare its key field to the one that is needed. The retrieval search ends only when the desired key matches with the key field of the currently read record.
(v) Hierarchical Database Structure: In a hierarchical database structure, records are logically organized in a hierarchy of relationships. A hierarchically structured database is arranged logically in an inverted tree pattern. All records in the hierarchy are called nodes. Each node is related to the others in a parent-child relationship. Each parent record may have one or more child records, but no child record may have more than one parent record. Thus, this structure implements one-to-one and one-to-many relationships. Entrance to the hierarchy is always made through the top parent record i.e. the root record. Ad hoc queries that require different relationships other than those already implemented in the database may be difficult or time consuming to accomplish. It usually processes structured, day-to-day operational data rapidly. It is suitable for large batch operations.
Network Database Structure: A network database structure views all records in sets. Each set is composed of an owner record and one or more member records. Thus, the network model implements the one-to-one and one-to-many record structures. However, unlike the hierarchical model, it also permits a record to be a member of more than one set at a time. This feature allows it to implement the many-to-one and many-to-many relationship types. It also allows us to create owner records without member records.
Unlike hierarchical data structures that require specific entrance points to find records in a hierarchy, network data structures can be entered and traversed more flexibly. However, like the hierarchical data model, the network model requires that record relationships be established in advance because these relationships are physically implemented by the DBMS when allocating storage space on disk. This is done to fit the processing needs of large batch reports. However, ad hoc requests for data, requiring record relationships not established in the data model, may not be very swift at all, and in some cases, they may not be possible.
(vi) RAM: Random Access Memory (RAM) is the memory system constructed with metal-oxide semi-conductor storage elements that can be charged. The purpose of RAM is to hold programs and data while they are in use. Access time in RAM is independent of the address of the word. One can reach into the memory at random and insert or remove numbers in any location at any time. It is extremely fast but can be quite expensive. RAMs can be further divided according to the way in which the data is stored, into dynamic RAM and static RAM. In dynamic RAM, each memory cell quickly loses its charge so it must be refreshed hundreds of times each second to prevent data from being lost. Static RAM is larger, faster and more expensive. It is static because it does not need to be continually refreshed. Because of its speed, it is mainly used in cache memory.
ROM: Read Only Memory (ROM) is used for micro programs not available to normal programmers. ROM refers to a storage that cannot be altered by regular program instructions. The information is stored permanently in such memory during manufacture. The information from the memory may be read out but fresh information cannot be written into it. ROM-BIOS is one such example. ROM is available in following three forms:
Programmable Read Only Memory (PROM) - PROM chip can be programmed once, thereafter, it cannot be altered.
Erasable Programmable Read Only Memory (EPROM) - EPROM chips can be electrically programmed. They can be erased using ultra-violet light and reprogrammed.
Electrically Erasable Programmable Read Only Memory (EEPROM) - It is similar to EPROM; the only difference is that the data can be erased by applying electrical charges.
|
S. No. |
Star Topology |
Ring Topology |
|
1. |
Processing nodes interconnect directly with a central system. Each node can communicate only with the central site and not with other nodes in the network. |
Processing nodes are connected in the form of a loop or ring. There is a direct unidirectional point-to-point link between two neighboring nodes. |
|
2. |
A node can transmit information to other node by sending the details to the central node, which in turn sends them to the destination. |
Since the links are unidirectional, transmission by a node traverses the whole ring and comes back to the node, which made the transmission. |
|
3. |
It is easy to add or remove computers. |
Adding or removing computers can disrupt the entire network. |
|
4. |
A node failure does not bring down the entire network, but if the central hub fails, the whole network ceases to function. |
A node failure can affect the whole network. |
|
5. |
It is easier to diagnose network problems through the central hub. |
It is difficult to troubleshoot a ring network. |
(viii)System Flowcharts: A system flowchart is designed to present an overview of the data flow through all parts of a data processing system. It represents the flow of documents, the operations or activities performed and the persons or workstations. It also reflects the relationship between inputs, processing and outputs. In a manual system, a system flowchart may comprise of several flowcharts prepared separately, such as document flowchart, activity flowchart etc. In a computer system, the system flowchart consists of mainly the following:
(a) the sources from which input data is prepared and the medium or device used,
(b) the processing steps or sequence of operations involved, and
(c) the intermediary and final output prepared and the medium and devices used for their storage.
Run Flowcharts: Run flowcharts are prepared from the system flowcharts and show the reference of computer operations to be performed. The chart expands the detail of each compute box on the system flowchart showing input files and outputs relevant to each run and the frequency of each run. The transactions in these applications are keyed on floppy disk and processed periodically against the master files to produce the desired reports, summaries projections etc. in a computer step. The transactions may have to be sorted before the file updating run. If these transactions are on off-line storage, these would be sorted by the key in which the master file has been arranged using sort utilities.
(ix) Intranet: An Intranet is a type of information system that facilitates communication within the organization, among widely dispersed departments, divisions and regional locations. Intranets connect people together with Internet technology, using Web browsers, Web servers and data warehouses in a single view. With an Intranet, access to all information, applications and data can be made available through the same browser. The objective is to organize each individual's desktop with minimal cost, time and effort to be more productive, cost-efficient, timely and competitive. An organization uses an Intranet to share information between the members of the organization.
Extranet: An Extranet is an extension of an Intranet that makes the latter accessible to outside companies or individuals with or without an Intranet. It is also defined as a collaborative Internet connection with other companies and business partners. Parts of an Intranet are made available to customers or business partners for specific applications. The Extranet is thus an extended Intranet, which isolates business communication from the Internet through secure solutions. Extranets provide the privacy and security of an Intranet while retaining the global reach of the Internet. An Extranet extends the Intranet from one location to another across the Internet by securing data flows using cryptography and authorization procedures, to another Intranet of a business partner. Organizations use Extranets to exchange information with and provide services to their business partners.
(x) B2B: B2B stands for Business-to-Business, the exchange of services, information and/or products from one business to another, as opposed to between a business and a consumer. B2B electronic commerce typically takes the form of automated processes between trading partners and is performed in much higher volumes than business-to-consumer (B2C) applications. It can also encompass marketing activities between businesses, and not just the final transactions that result from marketing. It is also used to identify sales transactions between businesses.
B2C: B2C stands for Business-to-Consumer, the exchange of services, information and/or products from a business to a consumer, as opposed to between one business and another. In B2C electronic commerce, products or services are sold from a firm to a consumer. It can save time and money by doing business electronically. It minimizes internal costs created by inefficient and ineffective supply chains and creates reduced end prices for the customers. Two classifications of B2C e-commerce are -
(a) Direct Sellers: Companies that provide products or services directly to customers are called direct sellers. There are two types of direct sellers: E-tailers and Manufacturers.
(b) Online Intermediaries: Online intermediaries are companies that facilitate transactions between buyers and sellers and receive a percentage. There are two types of online intermediaries: brokers and infomediaries.
| |||||||||||||||||||||||||||
|
(xii) Limited Entry Decision Table: In a limited entry decision table, the condition and action statements are complete. The condition and action entries merely define whether or not a condition exists or an action should be taken. The condition stub |
specifies exactly the condition or the value of the variable. The symbols used in the condition entries are:
Y : Yes, the condition exists.
N : No, the condition does not exist.
- : Irrelevant, the condition does not apply, or it (or blank)
makes no difference whether the condition exists or not.
The symbols used in the action entries are:
X : Execute the action specified by the (or blank) action
statement.
- or blank : Do not execute the action specified by the (or blank) action
statement.
Extended Entry Decision Table: The condition and action statements in an extended entry decision table are not complete, but are completed by the condition and action entries. In this, a portion of the condition (action) appears in the entry portion of the table. The condition stub cites the identification of the condition but not the particular values, which are entered directly into the condition entries. No particular symbols are used in such a table.
5. (a) Computers are helpful due to the following characteristics:
(i) Speed: Computer operations are measured in milliseconds, microseconds, nanoseconds, and picoseconds, which is relatively very fast as compared to what humans can achieve manually.
(ii) Accuracy: Accuracy is the degree to which information on a map or in a digital database matches true or known values. Errors do occur in computer-based information systems, but precious few can be directly attributed to the computer system itself. The vast majority can be traced to a program logic error, a procedural error, or erroneous data. These are human errors.
(iii) Reliability: Reliability can be defined as the ability of a system to perform and maintain its functions in routine circumstances, as well as in hostile or unexpected circumstances. Computer systems are particularly adept at repetitive tasks. They produce the same results always if same input is given.
(iv) Memory Capability: Computer systems have total and instant recall of data and an almost unlimited capacity to store these data. High-end PCs have access to about a billion characters of data.
But computers have certain limitations also, which are mentioned below.
(i) Program must be reliable: The computer does what it's programmed to do and nothing else. A clever program can be written to direct the computer to store the results of previous decisions. Then, by using the
program's branching ability, the computer may be able to modify its behavior according to the success or failure of past decisions. But a program that has operated flawlessly for months can suddenly produce nonsense due to some rare combination of events for which there's no programmed course of action or due to some error. Also, a reliable program that's supplied with incorrect data may also produce nonsense.
(ii) Application logic must be understood: The computer can only process jobs which can be expressed in a finite number of steps leading to a specific goal. Each step must be clearly defined. If the steps in the solution cannot be precisely stated, the job cannot be done. This is why the computer may not be helpful to people in areas where subjective evaluations are important.
(b) The various characteristics of storage along with the types of storage are:
(i) Volatility of information:
Volatile memory - It requires constant power to maintain the stored information.
Non-volatile memory - It retains the stored information even if it is not constantly supplied with electric power.
Dynamic memory - It is volatile memory which requires that stored information is periodically refreshed.
(ii) Ability to access non-contiguous information:
Random access memory - In this, any location can be accessed at any moment in the same, usually small, amount of time.
Sequential access memory - In this, accessing a piece of information takes a varying amount of time, depending on which piece of information was accessed last.
(iii) Ability to change information:
Read/write storage, or mutable storage - It allows information to be overwritten at any time.
Immutable storage -
Read only storage - It retains the information stored at the time of manufacture.
Write once storage (WORM) - It allows the information to be written only once at some point after manufacture.
Slow write, fast read storage - It is read/write storage which allows information to be overwritten multiple times, but with the write operation being much slower than the read operation.
(iv) Addressability of information:
Location-addressable storage - In this, each individually accessible unit of information is selected with its numerical memory address.
File system storage - In this, information is divided into files of variable length, and a particular file is selected with human-readable directory and file names. The underlying device is still location-addressable, but the operating system provides the file system abstraction to make the operation more understandable.
Content-addressable storage - In this, each individually accessible unit of information is selected with a hash value, or a short identifier pertaining to the memory address the information is stored on.
Storage capacity - It is the total amount of stored information in bits or bytes that a device can hold.
Storage density - It refers to the compactness of stored information.
Latency - It is the time taken to access a particular location in storage.
Throughput - It is the rate at which information can be read from or written to the storage.
For more details of the above points, students are advised to refer to the study material Chapter - 1, Unit - 1, Section - 1.6.2.
(c) The number of characters that can be stored on a floppy diskette by a disk drive is dependent on following three basic factors:
(i) The number of sides of the diskette used: Earlier diskettes and drives were designed so that data could be recorded only on one side of the diskette. These drives were called single-sided drives'. Now-a-days diskette drives are manufactured so that data can be read/written on both sides of the diskette. Such drives are called double-sided drives'. The use of double-sided drives and diskettes approximately doubles the number of characters that can be stored on the diskette.
(ii) The recording density of the bits on a track: The recording density refers to the number of bits that can be recorded on a diskette in one inch circumference of the innermost track on the diskette. This measurement is referred to as bits per inch (bpi). For the user, the diskettes are identified as being either single density (SD) or double density (DD).
(iii) The number of tracks on the diskette: The number of tracks depends upon the drive being used. Many drives record 40 tracks on the surface of the diskette. Other drives, however, can record 80 tracks on the diskette. These drives are sometimes called double track drives.
6. (a) A mouse is a small box, from the bottom of which protrudes a small ball bearing. The ball bearing rotates when the user moves the mouse across his desk and, as it is linked by a cable to the microcomputer, this moves the cursor on the display screen. A mouse may have one, two or three buttons. The function of each button is determined by the program that uses the mouse. In its simplest form, a mouse has one button. Moving the mouse moves the cursor on the screen, and clicking the button results in selecting an option. A mouse normally has two or three buttons, but the software package used by the user may use one, two or all three of them.
A mouse may be classified as a mechanical mouse or an optical mouse, depending on the technology it uses. In a mechanical mouse, the ball bearing that projects through the bottom surface rotates as the mouse is moved along a flat surface. The direction of rotation is detected and relayed to the computer by the switches inside the mouse. An optical mouse uses a light beam instead of a rotating ball to detect movement across a specially patterned mouse pad.
A serial mouse is connected to the PC through a serial port. A bus mouse is similar to a serial mouse except that it comes with a dedicated port and does not need a free serial port on the computer.
(b) Image processing is a process that captures an electronic image of data so that it can be stored and shared. Imaging system can capture almost anything such as handwritten documents, photographs, flow charts, drawings etc. There are five distinct steps to document imaging which are as follows:
Step 1: Data capture: The most common means of converting paper documents into electronic images is to scan them. The scanning device converts the text and pictures into digitized electronic code. The scanner can range from a simple hand held device to a high-end scanner. Hand-held scanners could transform text or graphical images into machine-readable data. Fax modems are also used to receive electronic images of documents. Some of today's low-speed printers and fax machines have removable print heads that can be replaced with a scanning head, enabling the printer to work as an image scanner.
Step 2: Indexing: Document images must be stored in a manner that facilitates their retrieval. Therefore, important document information, such as purchase order numbers or vendor numbers, is stored in an index. Great care is needed in designing the indexing scheme, as it affects the ease of subsequent retrieval of information.
Step 3: Storage: Because images require a large amount of storage space, they are usually stored on an optical disk. One 5.25-inch optical platter can store 1.4 GB, or about 25,000 documents. A 12-inch removable optical disk stores up to 60,000 documents, and up to 100 optical disks can be stored in devices called jukeboxes.
Step 4: Retrieval: Keying in any information stored in an index can retrieve documents. The index tells the system which optical disk to search and the requested information can be quickly retrieved.
Step 5: Output: An exact replica of the original document is easily produced on the computer's monitor or on paper, or is transmitted electronically to another computer.
7. (a) Operating system (OS) is a system software which acts as an interface between hardware and user. It has been devised to optimize the man-machine capabilities. It is defined as an integrated system of programs which supervises the operation of CPU, controls the input/output functions of computer system and provides various support services. Without loading it into the memory of the computer system, the computer cannot be used. It has two goals:
Resource allocator - The resources like processor, hard disk, memory etc. are allocated by the OS.
Control Program - The OS provides the environment for the execution of the program and prevents improper use of the computer.
There are six basic functions that an operating system can perform:
(i) Schedule Jobs: An OS determines the sequence in which different jobs are executed, using priorities established by the organization.
(ii) Manage Hardware and Software Resources: An OS first causes the user's application program to be executed by loading it into primary storage and then causes the various hardware units to perform as specified by the application.
(iii) Maintain System Security: OS identifies the authorized users by recognizing the password entered by the user and authorizes the user to have access to the system.
(iv) Enable Multiple User Resource Sharing: An OS can handle the scheduling and execution of the application programs for many users at the same time, a feature called multiprogramming.
(v) Handle Interrupts: An interrupt is a technique used by the OS to temporarily suspend the processing of one program in order to allow another program to be executed. Interrupts are issued when a program requests an operation that does not require the CPU, such as input/ output or when the program exceeds some predetermined time limit.
(vi) Maintain Usage Records: OS can keep track of the amount of time used by each user for each resource - CPU, secondary storage, and input and output devices. Such information is usually maintained for the purpose of charging users' departments for their use of the organization's computing resources.
(b) An expert system (ES) is a computerized information system that allows nonexperts to make decisions comparable to those of an expert. Expert systems are
used for complex or ill-structured tasks that require experience and specialized knowledge in narrow and specific subject areas.
Expert systems can be example-based, rule-based or frame-based.
Using an example-based system, developers enter the case facts and results. Through induction, the ES converts the examples into a decision tree that is used to match the case at hand with those previously entered in the knowledge base.
Rule-based systems are created by storing data and decision rules as if-then-else rules. The system asks questions to the user and then applies the rules to draw conclusions and make recommendations. These systems are appropriate when history of cases is unavailable or when a body of knowledge can be structured within a set of general rules.
Frame-based systems organize all the information into logical units called frames, similar to linked records in data files. Rules are then established about how to assemble or inter-relate the frames to meet the user's needs.
Expert systems typically contain the following components:
(i) Knowledge base: This includes the data, knowledge relationships, rules of thumb (heuristics), and decision rules used by experts to solve a particular type of problem. A knowledge base is the computer equivalent of all the knowledge and insight that an expert or a group of experts develop through years of experience in their field.
(ii) Inference engine: This program contains the logic and reasoning mechanisms that simulate the expert logic process and deliver advice. It uses data obtained from both the knowledge base and the user to make associations and inferences, form its conclusions, and recommend a course of action.
(iii) User interface: This program allows the user to design, create, update, use, and communicate with the expert system.
(iv) Explanation facility: This facility provides the user with an explanation of the logic the expert system used to arrive at its conclusion.
(v) Knowledge acquisition facility: Building a knowledge base, referred to as knowledge engineering, involves both a human expert and a knowledge engineer. The knowledge engineer is responsible for extracting an individual's expertise and using the knowledge acquisition facility to enter it into the knowledge base.
8. (a) The most widely used direct access techniques are depicted below:
Direct access
Random Access
Direct sequential Access
I
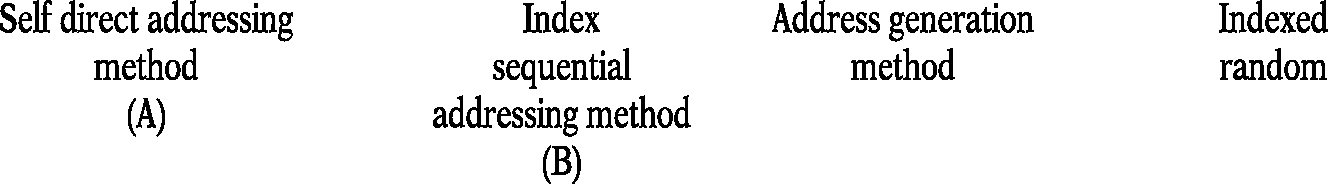 |
|
Direct Sequential Access Methods |
(A) Self (Direct) Addressing: Under self direct addressing, a record key is used as its relative address. Therefore, we can compute the record's address directly from the record key and the physical address of the first record in the file. Thus, this method is suitable for determining the bucket address of fixed length records in a sequential file, and in which the keys are from a complete or almost complete range of consecutive numbers.
Advantages:
There is no need to store an index.
Disadvantages:
The records must be of fixed length.
If some records are deleted, their storage space remains empty.
(B) Indexed-Sequential File Organization or Indexed Sequential Access Method (ISAM): In ISAM, the records within the file are stored sequentially but direct access to individual records is possible through an index. To locate a record, the cylinder index is searched to find the cylinder address, and then the track index for the cylinder is searched to locate the track address of the desired record.
Advantages:
It permits the efficient and economical use of sequential processing techniques when the activity ratio is high.
It permits direct access processing of records in a relatively efficient way when the activity ratio is low.
Disadvantages:
These files must be stored on a direct-access storage device. Hence, relatively expensive hardware and software resources are required.
Access to records may be slower than direct files.
It is less efficient in the use of storage space than some other alternatives.
Random Access Organization: In this method, transactions can be processed in any order and written at any location through the stored file. The desired records can be directly accessed using randomizing procedure without accessing all other records in the file.
Advantages:
The access to, and retrieval of a record is quick and direct.
Transactions need not be sorted and placed in sequence prior to processing.
Accumulation of transactions into batches is not required before processing them. They may be processed as and when generated.
It can also provide up-to-the minute information in response to inquiries from simultaneously usable online stations.
If required, it is also possible to process direct file records sequentially in a record key sequence.
A direct file organization is most suitable for interactive online applications such as airline or railway reservation systems, teller facility in banking applications, etc.
Disadvantages:
Address generation overhead is involved for accessing each record due to hashing function.
It may be less efficient in the use of storage space than sequentially organized files.
Special security measures are necessary for online direct files that are accessible from several stations.
(b) The selection of best file organization for a particular application depends upon the following factors:
(i) File volatility: It refers to the number of additions and deletions to the file in a given period of time. Applications which require large number of additions/deletions are called highly volatile. In such situation, perhaps sequential file organization would be appropriate if there were no interrogation requirements.
(ii) File activity: It is the proportion of master file records that are actually used or accessed in a given processing run. At one extreme is the real-time file where each transaction is processed immediately and hence at a time, only one master record is accessed. This situation obviously requires a direct access method. At the other extreme is a file, such as a payroll master file, where almost every record is accessed when the weekly payroll is processed. There, a sequentially ordered master file would be more efficient.
(iii) File interrogation: It refers to the retrieval of information from a file. If the retrieval of individual records must be fast to support a real-time operation such as airline reservation then some kind of direct organization is required. If, on the other hand, requirements for data can be delayed, then all the individual requests or information can be batched and run in a single processing run with a sequential file organization.
(iv) File size: Large files that require many individual references to records with immediate response must be organized under some type of direct access method. On the other hand, with small files, it may be more efficient to search the entire file sequentially or, with a more efficient binary search, to find an individual record than to maintain complex indexes or complex direct addressing scheme.
Payroll records of all employees should be stored sequentially since all records are to be accessed for payroll processing, direct accessing is not required.
9. (a) Earlier information systems had a file processing orientation. Therefore, data needed for each user application was stored in independent data files. Processing consisted of using separate computer programs that updated these independent data files and used them to produce the documents and reports required by each separate user application. This file processing approach has several problems that limit its efficiency and effectiveness for end user applications.
(i) Data Duplication: Independent data files include a lot of duplicated data; the same data is recorded and stored in several files. This data redundancy causes problems when data has to be updated, since separate file maintenance programs have to be developed and coordinated to ensure that each file is properly updated.
(ii) Lack of Data Integration: Having data in independent files makes it difficult to provide end users with information for ad hoc requests that require accessing data stored in several different files. Special computer programs have to be written to retrieve data from each independent file. This is difficult, time consuming and expensive for the organization.
(iii) Data Dependence: In file processing systems, major components of a system i.e. the organization of files, their physical locations on storage, hardware and the application software used to access those files depend on one another in significant ways. Thus, if changes are made in the format and structure of data and records in a file, changes have to be made in all programs that use this file. It is difficult and it results in a lot of inconsistency in the data files.
(iv) Other Problems: Data elements are generally defined differently by different end users and applications. This causes serious inconsistency in the development of programs, which access such data. In addition, the integrity of the data is suspected because there is no control over their use and maintenance by authorized end users.
The concepts of databases and database management were, hence, developed to solve these problems. A database is an integrated collection of logically related records and files. It consolidates records previously stored in independent files so that it serves as a common pool of data to be accessed by many different application programs.
Benefits of DBMS solution are:
|
(i) |
Reduced data redundancy and inconsistency |
|
(ii) |
Data sharing |
|
(iii) |
Enhanced data integrity |
|
(iv) |
Logical and physical data independence |
|
(v) |
Application data independence |
|
(vi) |
Reduced complexity of the organization's Information System environment |
|
(vii) |
Increased application programmer and user productivity |
(b) The database administrator is a database professional who actually creates,
maintains and coordinates the database. He has the overall authority to establish
and control data definitions and standards. He performs the following main
functions:
(i) Determines the relationships among data elements and designs the database security system to guard against unauthorized use.
(ii) Trains and assists application programmers in the use of database. Also educates end users, application programmers, operating staff and data administration personnel about their duties.
(iii) Discusses the data requirements with the users so that he can then decide the schedule and accuracy requirements, the way and frequency of data access, search strategies, physical storage requirements of data, level of security needed and the response time requirements.
(iv) Converts the user requirements into a physical design that specifies hardware resources required.
(v) Defines the contents (formats, relationships among various data elements and their usage) of the database using data definition language (DDL).
(vi) Provides for updating and changing the database, including the deletion of inactive records.
(vii) Maintains standards and controls access to database using DDL.
(viii) Prepares documentation which includes recording the procedures, standards, guidelines and data descriptions necessary for the efficient and continued use of the database environment.
(ix) Ensures that the operating staff performs its database processing related
responsibilities which include loading the database, following maintenance and security procedures, taking backups, scheduling the database for use and following restart and recovery procedures after some hardware or software failure, in a proper way.
(x) Ensures that the standards for database performance are being met and the accuracy, integrity and security of data are being maintained. He also sets up procedures for identifying and correcting violation of standards, documents and corrects errors.
(xi) Incorporates any enhancements into the database environment which may include new utility programs or new system releases, and changes into internal procedures for using database etc.
10. (a) A data warehouse is a computer database that collects, integrates and stores an organization's data with the aim of producing accurate and timely management information and supporting data analysis. It is a repository of an organization's electronically stored data. The concept was introduced to meet the growing demands for management information and analysis that could not be met by operational systems. Operational systems were unable to meet this need for a range of reasons:
The processing load of reporting reduced the response time of the operational systems,
The database designs of operational systems were not optimized for information analysis and reporting,
Most organizations had more than one operational system, so company-wide reporting could not be supported from a single system, and
Development of reports in operational systems often required writing specific computer programs which was slow and expensive.
As a result, separate computer databases began to be built that were specifically designed to support management information and analysis purposes. These data warehouses were able to bring in data from a range of different data sources and integrate this information in a single place. As technology improved and user requirements increased, data warehouses have evolved through several fundamental stages:
Offline Operational Databases - Data warehouses in this initial stage are developed by simply copying the database of an operational system to an offline server where the processing load of reporting does not impact the operational system's performance.
Offline Data Warehouse - Data warehouses in this stage are updated on a regular time cycle from the operational systems and the data is stored in an integrated reporting-oriented data structure.
Real Time Data Warehouse - Data warehouses at this stage are updated on a transaction or event basis, every time an operational system performs a transaction.
Integrated Data Warehouse - Data warehouses at this stage are used to generate activity or transactions that are passed back into the operational systems for use in the daily activity of the organization.
(b) Advantages of using data warehouse are:
Enhances end-user access to reports and analysis of information.
Increases data consistency.
Increases productivity and decreases computing costs.
Is able to combine data from different sources, in one place.
Provides an infrastructure that could support changes to data and replication of the changed data back into the operational systems.
Concerns in using data warehouse are:
Extracting, cleaning and loading data could be time-consuming.
Data warehouses can get outdated relatively quickly.
Problems in compatibility with systems already in place e.g. transaction processing system.
Providing training to end-users.
Security could develop into a serious issue, especially if the data warehouse is web accessible.
A data warehouse is usually not static and maintenance costs are high.
11. (a) A computer network is a collection of computers and terminal devices connected
together by a communication system.
Some of the ways in which a computer network can help a business are:
(i) File Sharing: File sharing consists of grouping all data files together on a server or servers. When all data files in an organization are concentrated in one place, it is much easier for staff to share documents and other data.
(ii) Print Sharing: When printers are made available over the network, multiple users can print to the same printer. This can reduce the number of printers the organization must purchase, maintain and supply. Network printers are often faster and more capable.
(iii) E-mail: Internal or "group" email enables staff in the office to communicate with each other quickly and effectively. Group email applications also provide capabilities for contact management, scheduling and task assignment.
(iv) Fax Sharing: Through the use of a shared modem(s) connected directly to the network server, fax sharing permits users to fax documents directly from their computers without ever having to print them out on paper. This reduces paper consumption and printer usage.
(v) Remote Access: Remote access allows users to dial in to their organization's network via telephone and access all of the same network resources they can access when they're in the office. Through the use of Virtual Private Networking (VPN), which uses the Internet to provide remote access to the network, even the cost of long-distance telephone calls can be avoided.
(vi) Shared Databases: A network makes the database available to multiple users at the same time. Sophisticated database server software ensures the integrity of the data while multiple users access it at the same time.
(vii) Fault Tolerance: Establishing fault tolerance is the process of making sure that there are several lines of defense against accidental data loss. This can be achieved by having redundant hardware, tape backup, uninterruptible power supply etc.
(viii) Internet Access and Security: When computers are connected via a network, they can share a common, network connection to the Internet. This facilitates email, document transfer and access to the resources available on the World Wide Web.
(ix) Communication and collaboration: A network allows employees to share files, view other people's work, and exchange ideas more efficiently. In a larger office, one can use e-mail and instant messaging tools to communicate quickly and to store messages for future reference.
(x) Organization: A variety of network scheduling software is available that makes it possible to arrange meetings without constantly checking everyone's schedules. This software usually includes other helpful features, such as shared address books and to-do lists.
(b) Communications software manages the flow of data across a network. It is written to work with a wide variety of protocols which are rules and procedures for exchanging data. It performs the following functions:
- Linking and disconnecting different devices
- Automatically dialing and answering telephones
- Restricting access to authorized users only
- Establishing parameters like speed, mode and direction of transmission
- Polling devices to see whether they are ready to send or receive data
- Queuing input and output
- Determining system priorities
- Routing messages
- Logging network activity, use, and errors.
(iii) Data and File Transmission: Controlling the transfer of data, files and messages among the various devices.
(iv) Error Detection & Control: Ensuring that the data sent was indeed the data received.
(v) Data Security: Protecting data during transmission from unauthorized access.
12. (a) A wireless local area network (WLAN) is a flexible data communications system implemented as an extension to a wired LAN. Using radio frequency (RF) technology, WLANs transmit and receive data over the air, minimizing the need for wired connections. With WLANs, users can access shared information without any plug-in or without any physical connection with wired infrastructure.
WLANs use electromagnetic airwaves (radio or infrared) to communicate information from one point to another. The data being transmitted is superimposed on the radio wave (radio carrier) so that it can be accurately extracted at the receiving end.
In a typical WLAN configuration, a transmitter/receiver (transceiver) device, called an access point, connects to the wired network from a fixed location using standard cabling. At a minimum, the access point receives, buffers, and transmits data between the WLAN and the wired network infrastructure. A single access point can support a small group of users and can function within a range of less than one hundred to several hundred feet. The access point (or the antenna attached to the access point) is usually mounted high but may be mounted essentially anywhere that is practical as long as the desired radio coverage is obtained. End users access the WLAN through wireless-LAN adapters, which are implemented as PC cards in notebook or palmtop computers, as cards in desktop computers, or integrated within hand-held computers. WLAN adapters provide an interface between the client network operating system (NOS) and the airwaves via an antenna.
(b) Following are the primary components of an Intrusion Detection System (IDS):
Network Intrusion Detection (NID): Network intrusion detection deals with information passing on the wire between hosts. Typically referred to as "packet-sniffers", NID devices intercept packets traveling along various communication mediums and protocols, usually TCP/IP. Once captured, the packets are analyzed in a number of different ways. Some NID devices will simply compare the packet to a signature database consisting of known attacks and malicious packet "fingerprints", while others will look for anomalous packet activity that might indicate malicious behavior.
Host-based Intrusion Detection (HID): Host-based intrusion detection systems are designed to monitor, detect, and respond to user and system activity and attacks on a given host. Some more robust tools also offer audit policy management and centralization, supply data forensics, statistical analysis and evidentiary support, and in certain instances provide some measure of access control.
Hybrid Intrusion Detection: Hybrid intrusion detection systems offer management of and alert notification from both network and host-based intrusion detection devices. Hybrid solutions provide the logical complement to NID and HID - central intrusion detection management.
Network-Node Intrusion Detection (NNID): Network-node intrusion detection was developed to work around the inherent flaws in traditional NID. Network-node pulls the packet-intercepting technology off the wire and puts it on the host. With NNID, the "packet-sniffer" is positioned in such a way that it captures packets after they reach their final target, the destination host. The packet is then analyzed. In this approach, network-node is simply another module that can attach to the HID agent. Network node's major disadvantage is that it only evaluates packets addressed to the host on which it resides.
13. (a) Limitations of traditional computing models which led to the emergence of
client/server technology:
(i) Mainframe architecture: With mainframe software architectures, all intelligence is within the central host computer (processor). Users interact with the host through a dumb terminal that captures keystrokes and sends that information to the host. Centralized host-based computing models allow many users to share a single computer's applications, databases, and peripherals. Mainframe software architectures are not tied to a hardware platform. User interaction can be done using PCs and UNIX workstations. A limitation of mainframe software architectures is that they do not easily support graphical user interfaces or access to multiple databases from geographically dispersed sites. They cost literally thousands of times more than PCs, but they sure don't do thousands of times more work.
(ii) Personal computers: Disconnected, independent personal computing models allow processing loads to be removed from a central computer. Besides not being able to share data, disconnected personal workstation users cannot share expensive resources that mainframe system users can share: disk drives, printers, modems, and other peripheral computing devices. The data (and peripheral) sharing problems of independent PCs and workstations, quickly led to the birth of the network/file server computing model, which links PCs and workstations together in a LAN, so they can share data and peripherals.
(iii) File sharing architecture: The original PC networks were based on file sharing architectures, where the server downloads files from the shared location to the desktop environment. The requested user job is then run in the desktop environment. The traditional file server architecture has many disadvantages especially with the advent of less expensive but more powerful computer hardware. The server directs the data while the workstation processes the directed data. Essentially this is a dumb server-smart workstation relationship. The server will send the entire file over the network even though the workstation only requires a few records in the file to satisfy the information request. In addition, an easy to use graphic user interface (GUI) added to this model simply adds to the network traffic, decreasing response time and limiting customer service. Also, the file server model does not support data concurrence that is required by multi-user applications. If many workstations request and send many files in a LAN, the network can quickly become flooded with traffic, creating a block that degrades overall system performance.
(b) A three-tier architecture consists of a client-tier, an application-server-tier and a data-server-tier. The application-server-tier provides process management where business logic and rules are executed.
Client-tier: It is responsible for the presentation of data, receiving user events and controlling the user interface.
Application-server-tier: Business-objects that implement the business rules "live" here, and are available to the client-tier. This tier protects the data from direct access by the clients.
Data-server-tier: This tier is responsible for data storage. Besides the widespread relational database systems, existing legacy systems databases are often reused here.
The boundaries between tiers are logical. It is quite easily possible to run all the three tiers on one and the same (physical) machine. The main importance is that the system is neatly structured, and that there is a well planned definition of the software boundaries between the different tiers.
Advantages of 3-tier architecture are:
Clear separation of user-interface-control and data presentation from application-logic: Through this separation more clients are able to have access to a wide variety of server applications. The two main advantages for client-applications are clear: quicker development through the reuse of prebuilt business-logic components and a shorter test phase, because the server-components have already been tested.
Dynamic load balancing: If bottlenecks in terms of performance occur, the server process can be moved to other servers at runtime.
Change management: It is easy and faster to exchange a component on the server than to furnish numerous PCs with new program versions. It is, however, compulsory that interfaces remain stable and that old client versions are still compatible. In addition such components require a high standard of quality control. This is because low quality components can, at worst, endanger the functions of a whole set of client applications.
Need for 3-tier architecture: In a 2-tier architecture, business-logic is implemented on the PC. Even the business logic never makes direct use of the windowing-system; programmers have to be trained for the complex API under Windows. The 2-tier-model implies a complicated software-distribution-procedure: as all of the application logic is executed on the PC, all those machines have to be updated in case of a new release. This can be very expensive, complicated, error-prone and time-consuming. Distribution procedures include the distribution over networks or the production of an adequate media like floppies or CDs. Once it arrives at the user's desk, the software first has to be installed and tested for correct execution. Due to the distributed character of such an update procedure, system management cannot guarantee that all clients work on the correct copy of the program. 3-tier architecture endeavors to solve these problems by moving the application logic from the client back to the server.
14. (a) A data center is a centralized repository for the storage, management and dissemination of data and information. Data centers can be defined as highly secure, fault-resistant facilities, hosting customer equipment that connects to telecommunications networks. The primary goal of a data center is to deploy the requisite state-of-the-art redundant infrastructure and systems so as to maximize availability and prevent or mitigate any potential downtime for customers.
The management of data center needs to face the following challenges:
(i) Maintaining a skilled staff and the high infrastructure needed for daily operations: A company needs to have staff which is expert at network management and has software/OS and hardware skills. The company has to employ a large number of such people, as they have to work on rotational shifts and for backups also.
(ii) Maximizing uptime and performance: While establishing sufficient redundancy and maintaining watertight security, data centers have to maintain maximum uptime and system performance.
(iii) Technology selection: The other challenges that enterprise data centers face is technology selection, which is crucial to the operations of the facility, keeping business objectives in mind. Another problem is compensating for obsolescence.
(iv) Resource balancing: The enterprise chief technical officer needs to strike a working balance between reduced operational budgets, increased demands on existing infrastructure, maximizing availability, ensuring round-the-clock monitoring and management, and the periodic upgrades that today's technology demands.
(b) A Business Continuity Plan (BCP) is a documented description of action, resources, and procedures to be followed before, during and after an event, functions vital to continue business operations are recovered, operational in an acceptable time frame.
Components of a BCP:
(i) Define requirements based on business needs,
(ii) Statements of critical resources needed,
(iii) Detailed planning on use of critical resources,
(iv) Defined responsibilities of trained personnel,
(v) Written documentations and procedures covering all operations,
(vi) Commitment to maintain plan to keep up with changes.
Life Cycle of BCP: The development of a BCP manual can have five main phases:
(i) Analysis
(ii) Solution design
(iii) Implementation
(iv) Testing and organization acceptance
(v) Maintenance
15. (a) The common applications of Internet can be classified into three primary types:
(i) Communication: Communication on the Internet can be online or offline. When some users connect to a single server or an on-line service at the same time, they can communicate in an "online chat. This can be truly "many-to-many as in a room full of people talking to each other on peer to peer basis. Alternatively, the users send e-mail to each other which can be read by the receiver at a later time. This is off-line communication, but "one-to-one or "one-to-many. It is also possible for the users to get together electronically with those sharing common interests in "Usenet groups.
(ii) Data Retrieval: For meaningful data retrieval, availability of data that has been compiled from various sources and put together in a usable form is an essential prerequisite. On the Internet, a large number of databases exist. These have been put together by commercially run data providers as well as individuals or groups with special interest in particular areas. To retrieve such
data, any user needs to know the addresses of such Internet servers. Then depending on the depth of information being sought, different databases have to be searched and required information compiled.
(iii) Data Publishing: Data publishing is a new opportunity that Internet has made possible. Information that needs to be made available to others can either be forwarded to specific addresses, posted in a Usenet site or kept on display in a special site. Internet discourages by social pressure, sending of unsolicited e-mails.
(b) Electronic mail (email) on the Internet provides quick, cost-effective transfer of
messages to other e-mail users worldwide. The email software comprises of many
important and useful features, some of which are as follows:
(i) Composing messages: With the help of Internet Browser, it is possible to compose messages in an attractive way with the help of various fonts. It is also possible to spell-check the message before finalizing it.
(ii) Replying to mails received: It is possible to reply to any mail received by merely using the "Reply facility available on the Internet Browser. This facility also allows one to send the same reply to all the recipients of the original message. This results in saving of a lot of time in terms of remembering addresses and also in typing the subject matter.
(iii) Address Book: This is an electronic form of address book wherein the following features can be saved: Name, full name, email address, name of organization and designation of person etc.
When one has to send the email, by merely typing the first name, it would be possible to recall the email address of the recipient. It is also possible to store addresses on the basis of categories.
(iv) Printing of messages: It is possible to print messages received as well as messages sent. As a result, hard copy of any message can also be kept.
(v) Offline Editing/Composing/Reading: One does not have to be connected to the Internet all the time to be able to read/edit/compose messages. Ideally, one should log on to the Internet, download all the messages onto one's own hard disk and then disconnect from the Internet. Once the user is offline, he should read all the messages that have been received. Even composing/editing/replying messages can be done offline. This saves Internet time as well as helps in keeping telephone lines free.
(vi) Forwarding of messages: It is possible to forward any message received from one user to another user without retyping the message.
(vii) Transfer of Data Files: Data files can be sent to/received from a client using email software. This results in considerable saving of time, energy and money.
(viii) Greeting Cards: On the Internet, there are several sites which offer free greeting cards for thousands of occasions. One has to visit the site, select a card and type the email address and name of the sender and recipient, and with a simple click, send the card.
16. (a) Reasons for Internet's dramatic impact on the scope of business networking applications:
(i) Universality - Any business using the Internet can interact with any other business using the Internet.
(ii) Reach - The Internet is everywhere; large cities and small towns throughout the modern and developing world.
(iii) Performance - The Internet provides its users with a high-function window to the world, in addition to handling everyday networking tasks such as electronic mail, visual images, audio clips and other large electronic objects.
(iv) Reliability - Internet technology is highly robust and reliable, in spite of significant differences in the extent to which various Internet service providers actually implement and ensure its reliability.
(v) Cost - Compared with alternative networking technologies, Internet costs are very low.
(vi) Momentum - The rate of growth of Internet users is increasing manifold every year, thus business use is increasing at a dramatic rate.
(b) Supply Chain Management encompasses the planning and management of all activities involved in sourcing and procurement, conversion, and all logistics management activities. Importantly, it also includes coordination and collaboration with channel partners, which can be suppliers, intermediaries, third-party service providers, and customers. In essence, Supply Chain Management integrates supply and demand management within and across companies.
Supply chain management must address the following problems:
(i) Distribution Network Configuration: Number and location of suppliers, production facilities, distribution centers, warehouses and customers.
(ii) Distribution Strategy: Centralized versus decentralized, direct shipment, cross docking, pull or push strategies, third party logistics.
(iii) Information: Integrate systems and processes through the supply chain to share valuable information, including demand signals, forecasts, inventory and transportation.
(iv) Inventory Management: Quantity and location of inventory including raw materials, work-in-process and finished goods.
(c) Electronic Data Interchange (EDI) is the transmission, in a standard syntax, of unambiguous information of business or strategic significance between computers of independent organizations. The users of EDI do not have to change their internal databases. However, users must translate this information to or from their own computer system formats, but this translation software has to be prepared only once. In simple terms, EDI is computer-to-computer communication using a standard data format to exchange business information electronically between independent organizations.
Working of EDI - EDI is a three step process:
(i) Sender data is translated into a standard format as defined by EDI translation software.
(ii) Data in standard format is transmitted over communication lines to the receiver.
(iii) Standard format data is translated according to the format of receiver database files.
EDI consists of three components:
(i) Communications: To make EDI work, one needs communications software, translation software and access to standards. Communications software moves data from one point to another, flags the start and end of an EDI transmission, and determines how acknowledgements are transmitted and reconciled. Translation software helps the user to build a map and shows him how the data fields from his application corresponds to the elements of an EDI standard. Later, it uses this map to convert data back and forth between the application format and the EDI format.
(ii) Mapping: To build a map, the user first selects the EDI standard appropriate for the kind of data he wants to transmit. Usually the trading partner (receiver) tells what standard to use. Next, he edits out parts of the standard which do not apply to his application. Next, he imports a file that defines the fields in his application, and finally he marks the map to show where the data required by the EDI standard is located in his application. Once the map is built, the translator will refer to it during EDI processing every time a transaction of that type is sent or received.
(iii) Profile: The last step is to write a partner profile that tells the system where to send each transaction and how to handle errors or exceptions. Whereas the user needs a unique map for every kind of document he exchanges with a partner, he should only have to define partner information once.
17. (a) Program analysis is an important step in computer programming in which the computer programmer seeks the answer to the question "What is the program supposed to do? Thus, first the programmer has to define the problem. The
problem needs to be defined and set for the computer in such a way that every possible alternative is taken care of. The computer procedure must be sufficiently detailed at each stage of a computation to permit the required calculations to be performed. The procedure for generating a sequence of Fibonacci numbers (that are less than 100) serves as an example:
(i) Assign the values: 0 to N1, 1 to N2. (continue with step (ii))
(ii) Write the value of N2. (continue with step (iii))
(iii) Add N1 and N2 and assign the resulting value to N3. (continue with step (iv))
(iv) If N3 is less than or equal to 100, then go to step (vi). If N3 is greater than 100, continue with step (v).
(v) Stop.
(vi) Write the value of N3. (continue with step (vii))
(vii) Assign the value of N2 to N1. (continue with step (viii))
(viii) Assign the value of N3 to N2. (continue with step (ix))
(ix) Go to step (iii).
Algorithm is a finite list of instructions specifying a sequence of operations which gives the answer to any problem of a given type. An algorithm exists for each computational problem that has a general solution. The algorithm for generating a sequence of Fibonacci numbers (that are less than 100) serves as an example:
|
(i) |
Set N1 to 0. |
|
(ii) |
Set N2 to 1. |
|
(iii) |
Write down N2. |
|
(iv) |
Set N3 equal to N1 + N2. |
|
(v) |
If N3 is greater than 100, then stop the calculations. |
|
(vi) |
Write down N3. |
|
(vii) |
Replace N1 by N2. |
(viii) Replace N2 by N3.
(ix) Continue the calculations with step 4.
(b) A flowchart helps in describing a complex problem. It is a diagrammatic representation of the sequence of steps involved in solving a problem. It is an essential tool for programming and it illustrates the strategy and thread of logic followed in the program. It allows the programmer to compare different approaches
and alternatives on paper and often shows interrelationships that are not immediately apparent. A flowchart helps the programmer avoid fuzzy thinking and accidental omissions of intermediate steps. Flowcharts can be divided into four categories as below:
(i) System outline charts (Global map): These charts merely lists the inputs, files processed and outputs without regard to any sequence whatever.
(ii) System flowcharts (National map): A system flowchart is designed to present an overview of the data flow through all parts of a data processing system. It represents the flow of documents, the operations or activities performed and the persons or workstations. It also reflects the relationship between inputs, processing and outputs. In a computer system, it consists of mainly the following:
the sources from which input data is prepared and the medium or device used
the processing steps or sequence of operations involved
the intermediary and final output prepared and the medium and devices used for their storage
(iii) Run flowcharts (State map): These are prepared from the system flowcharts and show the reference of computer operations to be performed. The chart expands the detail of each compute box on the system flow chart showing input files and outputs relevant to each run and the frequency of each run.
(iv) Program flowcharts (District map): These are the most detailed and are concerned with the logical/arithmetic operations on data within the CPU and the flow of data between the CPU on the one hand and the input/output peripherals on the other. The most detailed program flowchart would have exactly one instruction for each symbol in the flowchart i.e., coding would be simple and straightforward but the flowchart being biggish would defeat its purpose of showing the flow of data at a glance.
18. The required flowchart is given on the next page.
|
> |
f |
|
TAX = 0, SCHG=0, EC=0 | |
|
> |
f |
|
-<-< | ||
|
TAX=25,000+ 0.3*(INC-2,50,000) | ||
|
> |
f | |
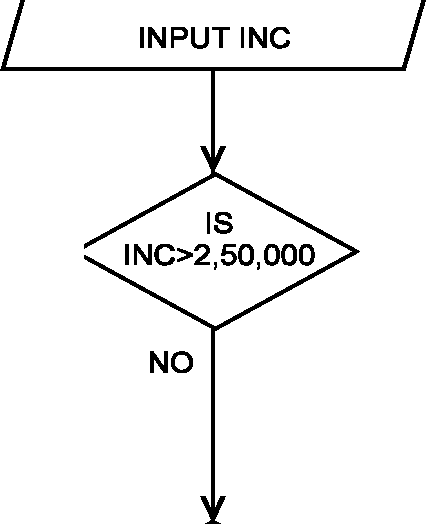 |
|
YES |
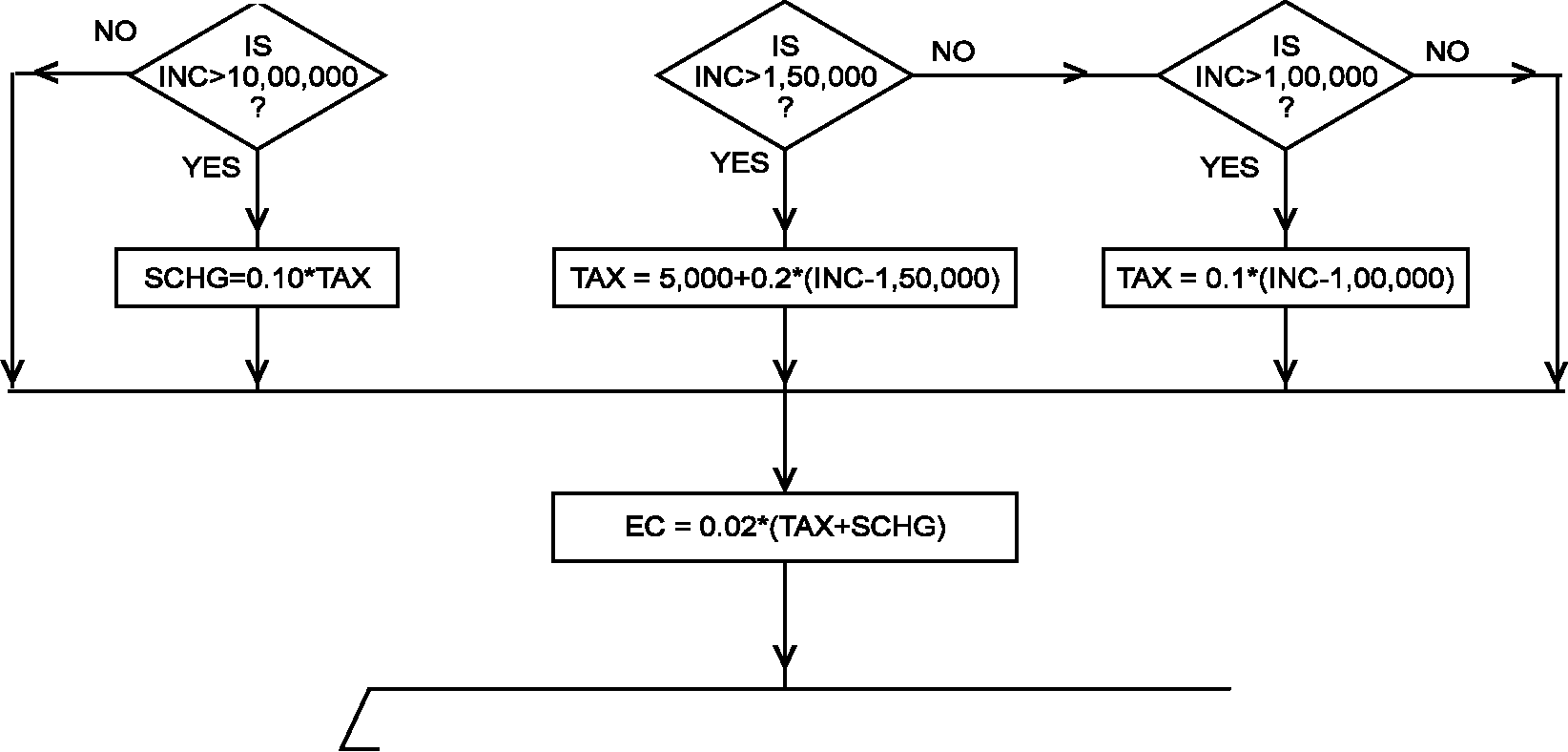 |
|
PRINT"TAX="; TAX, "SURCHARGE-'; SCHG, "ECESS="; EC ( STOP ) |
Symbols:
TAX
SCHG
EC
INC
Income Tax Surcharge Education cess Income
19. (a) A decision table is a table which defines the possible contingencies that may be considered within the program and the appropriate course of action for each contingency. It may accompany a flowchart.
A decision table has a number of advantages which are stated below:
(i) A decision table provides a framework for a complete and accurate statement of processing or decision logic. It forces a discipline on the programmer to think through all possible conditions.
(ii) A decision table may be easier to construct than a flowchart.
(iii) A decision table is compact and easily understood making it very effective for communication between analysts or programmers and non-technical users. Better documentation is provided by it.
(iv) Direct conversion of decision table into computer program is possible using available software packages.
(v) It is possible to check that all test combinations have been considered.
(vi) Alternatives are shown side by side to facilitate analysis of combinations.
(vii) The tables show cause and effect relationships.
(viii) They use standardized format.
(ix) Typists can copy tables with virtually no question or problems.
(x) Complex tables can easily be split into simpler tables.
(xi) Table users are not required to possess computer knowledge.
Disadvantages of using decision tables are as follows:
(i) Total sequence - The total sequence is not clearly shown, i.e., no overall picture is given by decision tables as presented by flowcharts.
(ii) Logic - Where the logic of a system is simple, flowcharts nearly always serve the purpose better than a decision table.
|
Rules |
R1 |
R2 |
R3 |
R4 |
R5 |
R6 | |
|
C1 |
Customer is a Dealer |
Y |
Y |
Y |
N |
N |
N |
|
C2 |
Pays bills within 30 days |
Y |
N |
N |
Y |
N |
N |
|
C3 |
Pays bills between 30 to 45 days |
- |
Y |
N |
- |
Y |
N |
|
C4 |
Pays bills after 45 days |
- |
- |
Y |
- |
- |
Y |
|
Actions | |||||||
|
A1 |
Discount 10% |
X | |||||
|
A2 |
Discount and Surcharge 0 |
X |
X | ||||
|
A3 |
Surcharge 10% |
X | |||||
|
A4 |
Discount 121/2% |
X | |||||
|
A5 |
Surcharge 121/2% |
X |
20. (i) OCR: Optical Character Reading (OCR) employs a set of printing characters with standard font that can be read by both human and machine readers. The machine reading is done by light scanning techniques in which each character is illuminated by a light source and the reflected image of the character is analyzed in terms of the light-dark pattern produced. Keyboard devices are used to give the required print quality. Optical character readers can read upper and lower case letters, numerals, and certain special characters from handwritten, typed and printed paper documents. The specific characters that can be read, depends upon the type of OCR being used. OCR annihilates the time consuming step of transcription. OCR characters can be sent as input to the CPU. Also, printers can be used to generate OCR output. Optical character readers can read from both cut form and continuous sheets. Large volume billing applications increasingly are being adapted to OCR methods.
Advantages of OCR:
(a) OCR eliminates the human effort of transcription.
(b) Paper work explosion can be handled because OCR is economical for a high rate of input.
(c) Since documents have only to be typed or handwritten, not very skilled staff is required.
(d) These input preparation devices are much cheaper than the keypunch or the key-to-tape devices.
Limitations of OCR:
(a) There are usually specific and rather inflexible requirements for type font and size of characters to be used.
(b) Most optical readers are not economically feasible unless the daily volume of transactions is relatively high.
(ii) Bullwhip Effect: The Bullwhip Effect or Whiplash Effect is an observed phenomenon in forecast-driven distribution channels. Because customer demand is rarely perfectly stable, businesses must forecast demand in order to properly position inventory and other resources. Forecasts are based on statistics, and they are rarely perfectly accurate. Because forecast errors are a given, companies often carry an inventory buffer called safety stock. Moving up the supply chain from end-consumer to raw materials supplier, each supply chain participant has greater observed variation in demand and thus greater need for safety stock. In periods of rising demand, down-stream participants will increase their orders. In periods of falling demand, orders will fall or stop in order to reduce inventory. The effect is that variations are amplified the farther you get from the end-consumer.
The alternative to forecast-driven supply chain is to establish a demand-driven supply chain which reacts to actual customer orders. The result is near-perfect visibility of customer demand and inventory movement throughout the supply chain.
|
(a) |
Forecast Errors |
|
(b) |
Lead Time Variability |
|
(c) |
Batch Ordering |
|
(d) |
Price Fluctuations |
|
(e) |
Product Promotions |
|
(f) |
Inflated Orders |
|
(g) |
Methods intended to reduce uncertainty, variability, and lead time |
|
(h) |
Vendor Managed Inventory (VMI) |
|
(i) |
Just In Time replenishment (JIT) |
|
(j) |
Strategic Partnership (SP) |
(iii) Program Library Management System Software:
(a) It provides several functional capabilities to effectively and efficiently manage data center software inventory which includes - Application Program Code, System Software Code, and Job Control Statements.
(b) It possesses integrity capabilities such that - each source program is assigned, a modification number is assigned, a version number is assigned, and it is associated with a creation date.
(c) It uses - Password, Encryption, Data Compression, and Automatic backup.
(d) It possesses update capabilities with the facilities of - addition, modification, deletion, and re-sequencing library numbers.
(e) It possesses reporting capabilities for being reviewed by the management and the end users by preparing lists of - additions, deletions, modifications, library catalogue, and library members attributes.
(f) It possesses interface capabilities with the - Operating System, Job scheduling system, Access control system, Online program management.
(g) It controls movement of program from test to production status.
(h) At last, it changes controls to application programs.
(iv) TCP/IP: Transmission Control Protocol / Internet Protocol (TCP/IP) are the
protocols used on the Internet. It has two parts:
(a) TCP deals with exchange of sequential data.
(b) IP handles packet forwarding.
TCP/IP has four layers:
(a) Application Layer - It provides services directly to the users such as e-mail.
(b) Transport Layer - It provides end-to-end communication between applications and verifies correct packet arrival.
(c) Internet Layer - It provides packet routing for error checking and addressing and integrity.
(d) Network Interface Layer - It provides an interface to the network hardware and device drivers.
TCP/IP creates a packet-switching network. When a message is ready to be sent over the Internet, the TCP protocol breaks it up into small packets. Each packet is then given a header, which contains the destination address. The packets are then sent individually over the Internet. The IP protocol guides the packets so that they arrive at the proper destination. Once there, the TCP protocol re-assembles the packets into the original message.
(v) Graph Plotter: A graph plotter is a device capable of tracing out graphs, designs and maps into paper and even into plastic or metal plates. A high degree of accuracy can be achieved, even up to one thousandth of an inch. Plotters may be driven on-line or off-line. Computer systems dedicated to design work often operate plotter on-line but systems used for other applications as well as graphic applications operate them off-line. There are two types of plotters:
Drum Plotter: A drum plotter plots on paper affixed to a drum. The drum revolves back and forth, and a pen suspended from a bar above moves from side-to-side taking up new plot positions or plotting as it moves. This device is suitable for routine graph plotting and also for fashion designs.
Flat-bed Plotter: On a flat-bed plotter, the paper lies flat. The bar on which the pen is suspended itself moves on a gantry to provide the necessary two-way movement. Color plotting is usually possible.
Plotters are now increasingly being used in applications like CAD, which requires high quality graphics on paper. A plotter can be connected to a PC through the parallel port. A plotter is very software-dependent and needs a lot of instructions for producing output.
115
|
Attachment: |
| Earning: Approval pending. |